
随着ChatGPT、GPT4、文心一言等大模型越来越被大家所关注。海天瑞声推出「优雅打工人ChatGPT」系列栏目,和大家聊一聊ChatGPT的「优雅」。
few weeks ago
打工人还沉浸在
「ChatGPT解放生产力」
「使用ChatGPT摸鱼一共几步」
的愉悦中

紧接着
OpenAI 研究人员提交报告
预言美国人约80%工作岗位和50%工作任务
会受到 AI 影响

仅5天后,高盛又发布报告
预测 AIGC 将使全球 3 亿工作岗位实现自动化
打工人听后
又开始瑟瑟发抖起来

高盛还说
它也会创造新就业机会
比如年薪百万的提示工程师
可能会在未来10年内使全球年度GDP增加7%

ChatGPT究竟何德何能
能让数亿打工人的心绪波动如此激烈
(明明都是些被社会锤炼过的老打工人了)
让我们来浅析一波
自从ChatGPT问世,打工人和学生党便开始沉浸于与ChatGPT聊天解闷,询问常识问题,并使用“小助手”辅助写写作业等互动上。
ChatGPT发布后仅4个月,3月15日OpenAI再投一枚重磅消息发布GPT-4。3月16日百度也紧随其后,发布了文言一心的内测版本。
从OpenAI官网了解到,GPT-4 比 GPT-3 能够更好地理解自然语言的细节和语义,生成准确和自然的文本。
此外,GPT-4增加了多模态处理功能,对图片能够准确识别和转义。比如输入一张下图左侧的图片,然后询问它:“如果拳击手套落下,将会发生什么?”ChatGPT能够给出符合常理且正确的回答:“拳击手套将集中木板,而小球会飞起。”

更令所有竞争对手目瞪口呆的是,就在GPT-4发布后的第二天,“卷王”微软宣布正在将该技术植入到微软办公软件中,该功能名为“Microsoft 365 Copilot”,可谓是“宁可累死自己也要卷死同行”的真实写照。

Copilot接入微软的多个商业应用程序中使用,包括我们打工人每天接触的Word、PowerPoint、Excel等。在Word中Copilot可以帮助用户扫描文档,快速提取有用的信息,节省采编、写作的时间;在Excel中可以帮助用户分析数据的趋势,在表格中突出显示关键的数据;另外它还可以在PowerPoint中根据用户需求快速生成幻灯片。简直可以称其为 真·智能化·全自动·办公小助手。
当国际上以大型语言模型(LLM)为主导的人工智能拉锯战进行的如火如荼时,国内各大互联网企业也蓄势待发,包括百度、腾讯、阿里巴巴、快手等在内的大型科技企业,争相预发布中国第一个ChatGPT模型,连李开复都公开宣布自己“参赛”。
国内企业中,百度的进展最为迅猛。在前文提到的3月16日百度发布会上,李彦宏宣布正式推出大型语言模型生成式人工智能产品“文心一言”。不仅能够生成高质量、流畅自然的中文文本,并具备多种应用场景,如智能客服、内容创作、语音识别等,展示了百度在大型语言模型领域的技术实力和创新能力。
浅析ChatGPT技术
简单来说,ChatGPT是一个大模型,对应大数据、强算力、好算法。

大数据
ChatGPT具有“场景通用性强、泛化能力好、能够自主学习”等功能,而这一切都是以海量数据为基石,算法模型通过从海量数据中获得先验知识,构建知识图谱,根据上下文关系从而生产出问题答案。
关于ChatGPT使用的数据,我们采访了ChatGPT本尊,它是这样回复的:

Q:ChatGPT用了多少数据集,数据从哪里来
A:作为GPT-3.5的一种变体,我使用了大量的数据集进行训练,包括来自网络的文本语料库、书籍、新闻文章、论文、博客、维基百科等。这些数据集是从公共领域和互联网上获取的。
我使用的主要数据集是OpenAI的专有数据集,包括Common Crawl、WebText、BooksCorpus和新闻文章数据集。这些数据集涵盖了广泛的主题和语言风格,可以让我学习各种不同的语言和文本风格。此外,我还使用了其他来源的数据集,例如维基百科和一些常见的开放数据集,例如电影评论数据集和新闻主题数据集。
总的来说,我使用了数万亿个令牌(tokens)的文本数据进行训练,这是我能够提供广泛的语言理解和生成能力的基础。

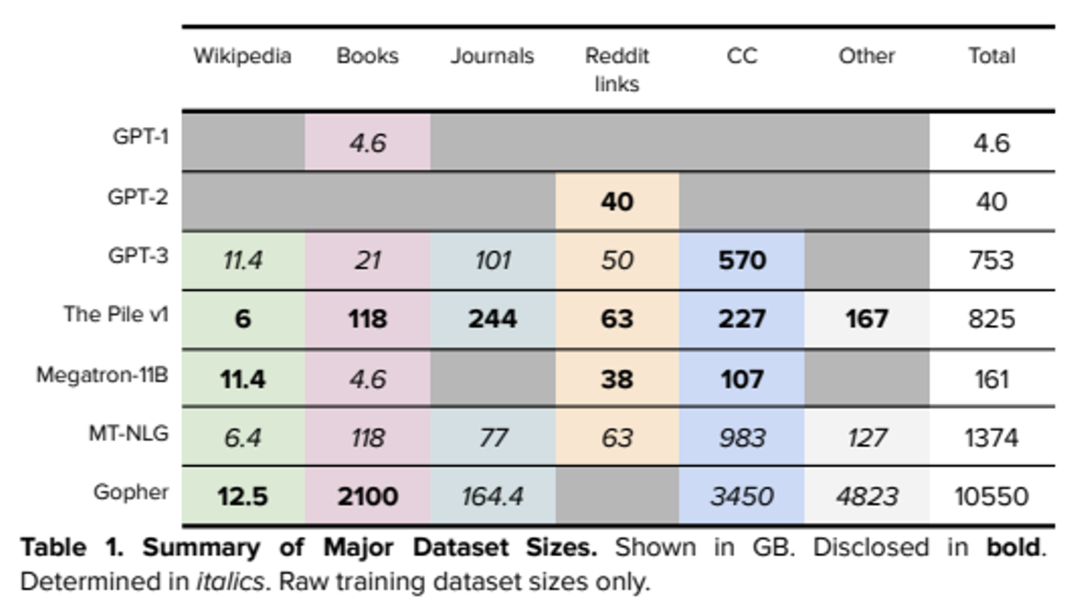
ChatGPT相关的论文阐述其所用数据如下所示[1]:
强算力
在训练ChatGPT模型的过程中,需要大量的计算资源来完成。据OpenAI官方信息,ChatGPT模型拥有1750多亿个参数 [2]。为了训练这个模型,OpenAI使用了多台超级计算机,包括由超过1万枚英伟达A100 GPU芯片的AI计算集群和Azure AI超算平台等。其中,微软Azure云服务为ChatGPT提供了计算资源,其超级计算机拥有超过28.5万个CPU核心、1万个GPU,并且每个GPU都有400Gbps的网络带宽 [3] ,可以为ChatGPT提供大规模分布式AI模型训练所需的巨大算力。

据OpenAI发布的数据显示,ChatGPT总算力消耗约为3640PF-days,这相当于每秒计算一千万亿次,需要计算3640天才能完成 [4]。可以看出,ChatGPT的训练需要大量的计算资源和时间,因此其训练成本非常高昂。
好算法
ChatGPT是一种基于深度学习的语言模型,它采用了一种被称为Transformer的架构。Transformer是一种基于自注意力机制的神经网络结构,用于解决序列到序列的任务,例如机器翻译和自然语言处理。相对于之前的递归神经网络和卷积神经网络,Transformer在处理长序列时效果更好,能够并行化处理,提高了计算效率。
ChatGPT的核心算法是语言模型,即用来预测下一个单词或字符的模型。它的训练目标是最大化给定输入序列的条件概率,也就是给定前面的词语,预测下一个词语的概率。

ChatGPT使用了一种被称为“预训练 + 微调”的训练方法。在预训练阶段,模型会在大量的文本数据上进行无监督学习,目标是学习语言中的模式和规律。在微调阶段,模型会在特定的任务上进行有监督学习,例如文本分类、语言生成等,以适应具体的应用场景。
在具体的算法实现上,ChatGPT采用了多层Transformer编码器作为基本单元,每个编码器包含了多头自注意力机制和前向神经网络两部分。自注意力机制用于处理输入序列中每个位置之间的关系,前向神经网络用于对每个位置进行局部的特征提取和转换。
算法、算力、数据是推动人工智能高速发展的三驾马车,训练ChatGPT这种超大规模往往不属于一个人或者一个成型的商品,需要公司日积月累以及专业的数据公司的采集、清洗、整理、分析和标注。

数据
是训练一切大模型的基石
如果想追赶国外的ChatGPT,数据积累是关键。数据是ChatGPT之类大模型训练的基础,它们是大模型学习语言模式和语义理解的来源。
如果数据不够丰富或者不够准确,大模型将无法准确的进行语言模型和语义学习,导致大模型的质量下降。并且这些模型需要大量多样化的数据才能进行训练,这些数据可以来自于不同的领域和不同的语言,从而提升模型的泛化能力,通用性和鲁棒性。
通过使用多样性的数据进行训练,大模型才能够更好的理解各种语言和领域的语言特征。其中数据的准确性对于大模型的训练也非常重要。
如果数据存在错误或者噪声,这些错误和噪声将会被大模型所学习并产生负面影响,导致模型的性能下降。
随着时间的推移,语言和语义理解的方式也会不断变化,实时性对于大模型的训练来说也非常重要。及时更新数据可以保持线上大模型的学习和推理能力,使其保持最新的语言和语义理解。
那么如何积累如此庞大规模的数据呢?
采集互联网数据
通过技术手段可以从互联网上收集大量的数据,但需要注意法律和伦理问题,避免侵犯个人隐私或违反版权法。同时,要注意采集速度和频率,避免对网站造成不必要的压力或影响用户体验。最后一步则是对采集数据进行处理和清洗,删除无效或不良数据,从中提取有效信息。
数据合成
数据合成指的是用生成模型AIGC的深度学习模型合成语音、图像、文本、多媒体视频数据,再用这些数据辅助通用大模型的训练。虽然这些合成的数据不是从现实世界中采集或测量的,但合成数据能够从数学或统计学上反映真实数据。
数据定制
根据企业不同的场景需求,数据公司可以基于自身对于行业客户的理解及专业积累,为企业提供相关咨询建议,并为企业量身打造安全合规的专业数据。
从2016年Google AlphaGo打败柯洁,到今天OpenAI 的ChatGPT和GPT-4 , 人工智能不断突破人类的想象,逐渐走入日常生活。相信会有更多超越期待的产品在研发的路上,不断扩宽我们的认知边界,刷新我们的感官体验。
文献参考
[1] Why Does Surprisal From Larger Transformer- d Language Models Provide a Poorer Fit to Human Reading Times? https://arxiv.org/abs/2212.12131
[2] Language Models are Few-Shot Learners, 2020, 6.3 Energy Usage, https://arxiv.org/pdf/2005.14165.pdf
[3] Microsoft announces new supercomputer, lays out vision for future AI work, https://news.microsoft.com/source/features/ai/openai-azure-supercomputer/
[4] GPT-3: The Dream Machine in the Real World, https://towardsdatascience.com/gpt3-the-dream-machine-in-real-world-c99592d4842f
